44 keras reuters dataset labels
PDF Introduction to Keras - AIoT Lab Load the Reuters Dataset •Select 10,000 most frequently occurring words 38 from keras.datasets import reuters (train_data, train_labels), (test_data, test_labels) = reuters.load_data(num_words=10000) Decode the News •Decode the word ID list back into English 39 Building your First Neural Network on a Structured Dataset (using Keras ... Load Data: Here, I'll import the necessary libraries to load the dataset, combine train and test to perform preprocessing together, and also create a flag for the same. #Importing Libraries for ...
Keras for R - RStudio The dataset also includes labels for each image, telling us which digit it is. For example, the labels for the above images are 5, 0, 4, and 1. Preparing the Data. The MNIST dataset is included with Keras and can be accessed using the dataset_mnist() function. Here we load the dataset then create variables for our test and training data:

Keras reuters dataset labels
TensorFlow - tf.keras.datasets.reuters.load_data - Loads the Reuters ... This is a dataset of 11,228 newswires from Reuters, labeled over 46 topics. This was originally generated by parsing and preprocessing the classic Reuters-21578 dataset, but the preprocessing code is no longer packaged with Keras. See this github discussion for more info. Each newswire is encoded as a list of word indexes (integers). Where can I find topics of reuters dataset #12072 - GitHub In Reuters dataset, there are 11228 instances while in the dataset's webpage there are 21578. Even in the reference paper there are more than 11228 examples after pruning. Unfortunately, there is no information about the Reuters dataset in Keras documentation. Is it possible to clarify how this dataset gathered and what the topics labels are? Datasets - Keras Datasets The tf.keras.datasets module provide a few toy datasets (already-vectorized, in Numpy format) that can be used for debugging a model or creating simple code examples. If you are looking for larger & more useful ready-to-use datasets, take a look at TensorFlow Datasets. Available datasets MNIST digits classification dataset
Keras reuters dataset labels. Creating and deploying a model with Azure Machine Learning Service ... Above, you simply use the reuters class of keras.datasets and use the load_data method to get the data and directly assign it to variables to hold the train and test data plus labels. In this case, the data consists of newswires with a corresponding label that indicates the category of the newswire (e.g. an earnings call newswire). Python keras.datasets.reuters.load_data() Examples def load_retures_keras(): from keras.preprocessing.text import Tokenizer from keras.datasets import reuters max_words = 1000 print('Loading data...') (x, y), (_, _) = reuters.load_data(num_words=max_words, test_split=0.) print(len(x), 'train sequences') num_classes = np.max(y) + 1 print(num_classes, 'classes') print('Vectorizing sequence data..... Reuters | Kaggle If you publish results based on this data set, please acknowledge its use, refer to the data set by the name 'Reuters-21578, Distribution 1.0', and inform your readers of the current location of the data set." What is keras datasets? | classification and arguments - EDUCBA Keras datasets as an extension to TensorFlow include a module or library with tf.keras.datasets that are used for modeling and fitting data related to models with Artificial intelligence and deep learning. This library helps in providing actual and appropriate data as per the need of the model.
keras/reuters.py at master · keras-team/keras · GitHub This is a dataset of 11,228 newswires from Reuters, labeled over 46 topics. This was originally generated by parsing and preprocessing the classic Reuters-21578 dataset, but the preprocessing code is no longer packaged with Keras. See this [GitHub discussion] ( ) for more info. Datasets in Keras - GeeksforGeeks Jul 07, 2020 · CIFAR10 (classification of 10 image labels): This dataset contains 10 different categories of images which are widely used in image classification tasks. It consists The dataset is divided into five training batches , each with 10000 images. The test batch contains exactly 1000 randomly-selected images from each class. Introduction to Keras, Part One: Data Loading Keras comes with a few in-built datasets — cleaned and vectorized, to help you build simple deep learning models. MNIST, CIFAR10, CIFAR100, IMDB, Fashion MNIST, Reuters newswire, and Boston housing price datasets are available within Keras. Classifying Reuters Newswire Topics with Recurrent Neural Network The purpose of this blog is to discuss the use of recurrent neural networks for text classification on Reuters newswire topics. The dataset is available in the Keras database. It consists of 11,228...
Keras - Model Compilation - tutorialspoint.com Line 1 imports minst from the keras dataset module. Line 3 calls the load_data function, which will fetch the data from online server and return the data as 2 tuples, First tuple, (x_train, y_train) represent the training data with shape, (number_sample, 28, 28) and its digit label with shape, (number_samples, ) . PDF Introduction to Keras - aiotlab.org from keras.utils import to_categorical trn_labels = to_categorical(train_labels) tst_labels = to_categorical(test_labels) ... Load the Reuters Dataset •Select 10,000 most frequently occurring words 42 from keras.datasets import reuters (train_data, train_labels), (test_data, test_labels) = dataset_mnist: MNIST database of handwritten digits in keras: R ... Path where to cache the dataset locally (relative to ~/.keras/datasets). Value. ... (num_samples, 28, 28) and y is an array of digit labels (integers in range 0-9) with shape (num_samples). ... , dataset_cifar10(), dataset_fashion_mnist(), dataset_imdb(), dataset_reuters() keras documentation built on May 23, 2022, 5:06 p.m. Related to dataset ... How to show topics of reuters dataset in Keras? - Stack Overflow Associated mapping of topic labels as per original Reuters Dataset with the topic indexes in Keras version is: ['cocoa','grain','veg-oil','earn','acq','wheat','copper ...
Rhyme - Project: Multilayer Perceptron Models with Keras
TensorFlow - tf.keras.datasets.mnist.load_data - Loads the MNIST dataset. tf.keras.datasets.mnist.load_data ( path= 'mnist.npz' ) This is a dataset of 60,000 28x28 grayscale images of the 10 digits, along with a test set of 10,000 images. More info can be found at the MNIST homepage. Returns Tuple of NumPy arrays: (x_train, y_train), (x_test, y_test).

Parse UCI reuters 21578 dataset into Keras dataset · GitHub - Gist parse_reuters.py This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.

Reuters newswire classification dataset - Keras This is a dataset of 11,228 newswires from Reuters, labeled over 46 topics. This was originally generated by parsing and preprocessing the classic Reuters-21578 dataset, but the preprocessing code is no longer packaged with Keras. See this github discussion for more info. Each newswire is encoded as a list of word indexes (integers).

Brad Dickinson | Creating and deploying a model with Azure Machine Learning Service
Datasets - Keras Documentation - faroit Fraction of the dataset to be used as test data. This dataset also makes available the word index used for encoding the sequences: word_index = reuters.get_word_index (path= "reuters_word_index.pkl" ) Return: A dictionary where key are words (str) and values are indexes (integer). eg. word_index ["giraffe"] might return 1234.

Data Augmentation tasks using Keras for image data | by Ayman Shams | Medium
keras source: R/datasets.R The `dataset_reuters_word_index ()` #' function returns a list where the names are words and the values are #' integer. e.g. `word_index [ ["giraffe"]]` might return `1234`. #' #' @family datasets #' #' @export dataset_reuters <- function (path = "reuters.npz", num_words = NULL, skip_top = 0L, maxlen = NULL, test_split = 0.2, seed = 113L, start_...

Image Classification using CNNs in Keras | Learn OpenCV
tf.keras.utils.text_dataset_from_directory | TensorFlow v2.9.1 Overview; LogicalDevice; LogicalDeviceConfiguration; PhysicalDevice; experimental_connect_to_cluster; experimental_connect_to_host; experimental_functions_run_eagerly
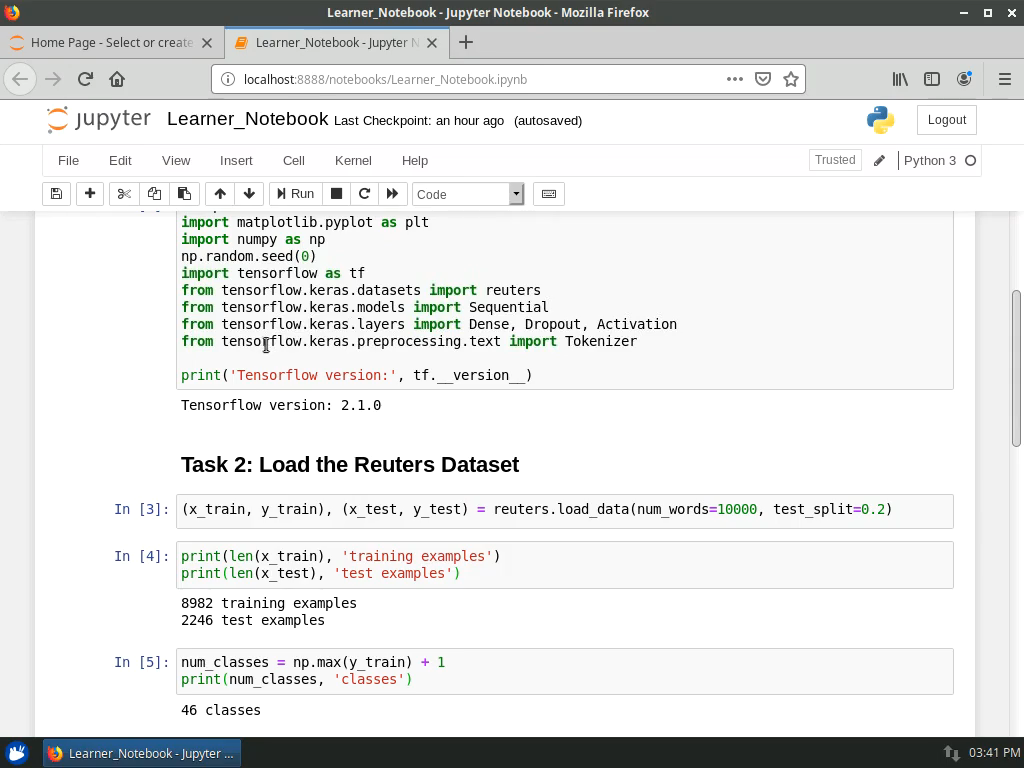
Rhyme - Project: Multilayer Perceptron Models with Keras
Datasets - keras-contrib - Read the Docs Fraction of the dataset to be used as test data. This dataset also makes available the word index used for encoding the sequences: word_index = reuters.get_word_index (path= "reuters_word_index.json" ) Returns: A dictionary where key are words (str) and values are indexes (integer). eg. word_index ["giraffe"] might return 1234.
keras image data generator tutorial | keras imagedatagenerator example
Keras for Beginners: Implementing a Recurrent Neural Network Keras is a simple-to-use but powerful deep learning library for Python. In this post, we'll build a simple Recurrent Neural Network (RNN) and train it to solve a real problem with Keras.. This post is intended for complete beginners to Keras but does assume a basic background knowledge of RNNs.My introduction to Recurrent Neural Networks covers everything you need to know (and more) for this ...
ImageDataGenerator.flow_from_dataframe keeps loading when directory has subdirectories · Issue ...
GitHub - kk7nc/Text_Classification: Text Classification ... from keras. layers import Input, Dense from keras. models import Model # this is the size of our encoded representations encoding_dim = 1500 # this is our input placeholder input = Input (shape = (n,)) # "encoded" is the encoded representation of the input encoded = Dense (encoding_dim, activation = 'relu')(input) # "decoded" is the lossy ...
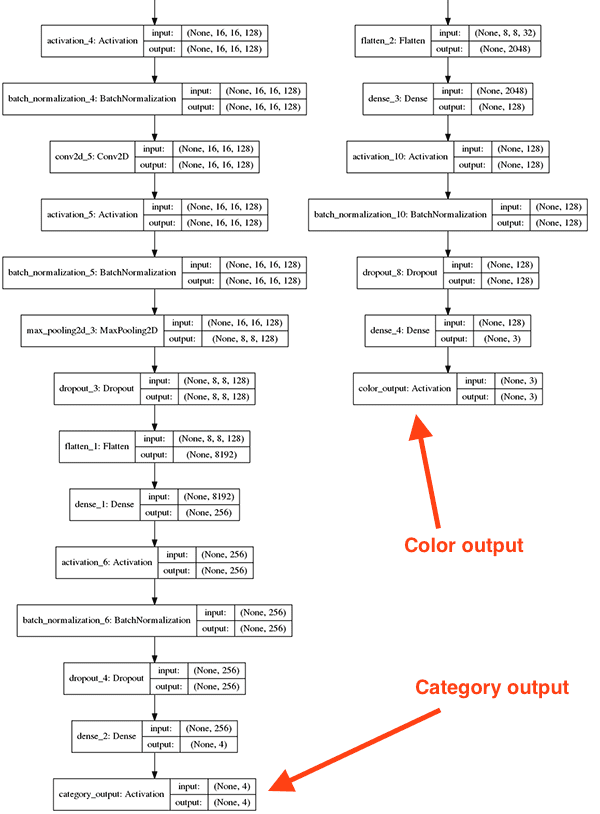
31 Keras Multi Label Classification - Labels For You
Is there a dictionary for labels in keras.reuters.datasets? I managed to get an AI running that predicts the classes of the reuters newswire dataset. However, I am desperately looking for a way to convert my predictions (intgers) to topics. There has to be a dictionary -like the reuters.get_word_index for the training data- that has 46 entries and links each integer to its topic (string). Thanks for ...

keras - Actual number of iterations - Data Science Stack Exchange
Tutorial On Keras Tokenizer For Text Classification in NLP To do this we will make use of the Reuters data set that can be directly imported from the Keras library or can be downloaded from Kaggle. This data set contains 11,228 newswires from Reuters having 46 topics as labels. We will make use of different modes present in Keras tokenizer and will build deep neural networks for classification.

Classifying Reuters Newswire Topics with Recurrent Neural Network | by Phuong Truong | Medium
Text Classification in Keras (Part 1) — A Simple Reuters News ... Part 1 in a series to teach NLP & Text Classification in Keras The Tutorial Video If you enjoyed this video or found it helpful in any way, I would love you forever if you passed me along a dollar or two to help fund my machine learning education and research!

Datasets - Keras Datasets The tf.keras.datasets module provide a few toy datasets (already-vectorized, in Numpy format) that can be used for debugging a model or creating simple code examples. If you are looking for larger & more useful ready-to-use datasets, take a look at TensorFlow Datasets. Available datasets MNIST digits classification dataset
Cara Membuat Mail Merge di Word 2007 - 2010 ~ GORESAN TINTA EMAS
Where can I find topics of reuters dataset #12072 - GitHub In Reuters dataset, there are 11228 instances while in the dataset's webpage there are 21578. Even in the reference paper there are more than 11228 examples after pruning. Unfortunately, there is no information about the Reuters dataset in Keras documentation. Is it possible to clarify how this dataset gathered and what the topics labels are?

TensorFlow - tf.keras.datasets.reuters.load_data - Loads the Reuters ... This is a dataset of 11,228 newswires from Reuters, labeled over 46 topics. This was originally generated by parsing and preprocessing the classic Reuters-21578 dataset, but the preprocessing code is no longer packaged with Keras. See this github discussion for more info. Each newswire is encoded as a list of word indexes (integers).
cannot import name 'detect_lp' · Issue #14208 · keras-team/keras · GitHub

Sample Gallery — zetane documentation
Post a Comment for "44 keras reuters dataset labels"